What Is Retrieval-Augmented Generation (RAG)? How
It Works

Learn how RAG (Retrieval-Augmented Generation) overcomes AI limits by using real-time data, reducing hallucinations, and delivering accurate insights.


Table of Contents
Share This Article

Artificial intelligence is reshaping how we search, learn, and solve problems. Yet for all its progress, traditional language models still suffer from a major flaw: they rely entirely on the data they were trained on, and their "knowledge" is frozen in time. This leads to outdated answers, missing context, and occasionally, confidently delivered inaccuracies. This is where RAG (Retrieval-Augmented Generation), one of the most important breakthroughs in modern AI, comes in.
Today, RAG is the engine behind enterprise chatbots and research tools that power personalized assistants and autonomous agents. It has become the backbone of advanced AI applications as it delivers the information that users and organizations want: accurate, current, relevant, and contextually aware data.
This comprehensive guide will examine what Retrieval-Augmented Generation means and how it functions; why it addresses fundamental limitations of AI with solutions; examples of RAG in use in the real world; challenges to RAG; and how it will affect the future of intelligent systems.
Why Traditional AI Needed a Better Approach
To understand the significance of RAG (Retrieval-Augmented Generation), let's start with the limitations of conventional large language models.
The Problem of Frozen Knowledge
Every language model has a Knowledge Cut-off, the date beyond which the model has no training data. No matter how powerful or well-trained an LLM is, it can't know what it hasn't seen.
If new laws pass, scientific discoveries emerge, or industry standards evolve, the model simply doesn't know. It may try to infer these updates or guess based on patterns, but that leads directly into the second problem.
The Challenge of Hallucinations
LLMs are brilliant at generating coherent language, but sometimes they generate content that sounds convincing yet is factually incorrect. This is Hallucination. It might seem harmless, but it can have devastating effects in certain fields like healthcare or legal compliance.
The hallucination decreases in a scenario when models become more advanced. But it will never be completely eliminated unless they are based on real and verifiable information. This is what RAG (Retrieval-Augmented Generation) provides, which is why it is now a core topic covered in many advanced AI learning paths, including a prompt engineering course focused on grounding and context-aware AI responses.
The Corporate Data Gap
LLMs also don't have access to proprietary, private, or internal company data. They cannot naturally understand:
- employee handbooks
- product manuals
- support logs
- technical schematics
- financial records
- internal policies
This contributes to today's corporate gaps, leaving organizations unable to leverage AI for one of its biggest promises: making sense of their own knowledge.
Thus, a new architecture was needed, one that allowed LLMs to combine their reasoning abilities with reliable, real-time information.
What Retrieval-Augmented Generation Means
RAG is an AI architecture that enhances generative models by retrieving information. The system does not rely on the remembered data of the model, but rather retrieves relevant and factual information from databases or other knowledge sources.
It is simplified as:
RAG = Retrieval Engine (search) + LLM (generation)
The retrieval engine finds the most relevant information, and the generative model uses that information to produce a final and context-aware response.
This means RAG (Retrieval-Augmented Generation) can answer questions using:
- newly published research
- updated guidelines
- internal company data
- user manuals
- policy documents
- web content
- structured or unstructured text
It fully bypasses the limitations of static knowledge and prevents the model from inventing details.
How Retrieval-Augmented Generation Works
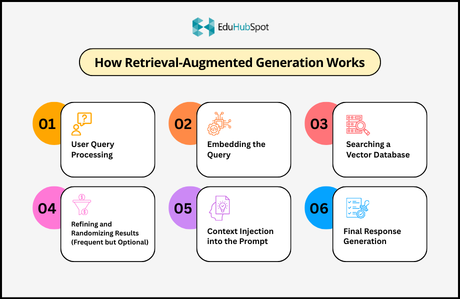
The RAG concept may seem simple, but the pipeline is actually a complex system of steps that all need to work in harmony.
Step 1: User Query Processing
A user types a question such as: "What does the latest European AI Act say about high-risk systems?"
Instead of answering immediately, the system prepares the query for retrieval.
Step 2: Embedding the Query
The LLM converts a query into a numerical representation known by the name of an embedding. These allow the retrieval system not only to match keywords, but also to find documents that are conceptually similar.
Step 3: Searching a Vector Database
These embeddings are compared to millions of pre-stored document embeddings in a vector database.
Popular vector databases for RAG (Retrieval-Augmented Generation) include:
- Pinecone
- FAISS
- Weaviate
- Milvus
- Elasticsearch vector engine
The Database will return the most relevant documents. They are called "contexts" or "chunks" or "passages".
Step 4: Refining and Randomizing Results (Frequent but Optional)
Sometimes the original search results are rescored by using a second model. The LLM will only receive the best and most relevant information. This step is used by advanced systems to improve the accuracy of their answers.
Step 5: Context Injection into the Prompt
The retrieved documents are inserted into the LLM's context window.
The prompt now contains:
- the user's question
- relevant supporting documents
- Instructions for how to answer
Step 6: Final Response Generation
The LLM reads the documents, analyzes the question, and generates a final, grounded answer.
This eliminates most Hallucination issues because the model is no longer guessing; it's referencing real information.
Why RAG (Retrieval-Augmented Generation) Is So Transformative
RAG is more than a feature; it's a paradigm shift. Here's why the industry has adopted it so rapidly.
Eliminates the Knowledge Freeze
Because RAG retrieves from dynamic data sources, it overcomes the Knowledge Cut-off entirely.
The model can pull information updated seconds earlier, allowing AI systems to stay current without expensive retraining.
Reduces Hallucinations
Grounding answers in real documents massively reduces Hallucination.
Users can even be shown the exact passages the model relied on, bringing transparency and trust.
Works Seamlessly with Proprietary Data
Organizations want AI that understands their business.
RAG (Retrieval-Augmented Generation) enables this through secure retrieval over:
- policy libraries
- CRM systems
- support tickets
- financial statements
- legal archives
This brings unprecedented value to enterprise AI.
Cheaper and Faster Than Updating LLMs
Retraining an LLM is extremely expensive.
Updating a vector database?
It is fast, simple, and inexpensive.
Retrieval-Augmented Generation gives companies agility and control.
Allows Explainable AI
Since retrieved documents can be traced, RAG offers explainability—essential in regulated industries such as finance, law, and healthcare.
Because of these benefits, RAG is now considered a foundational concept in professional learning paths, such as a gen ai certification aimed at building production-ready AI systems.
Types of RAG (Retrieval-Augmented Generation) Models
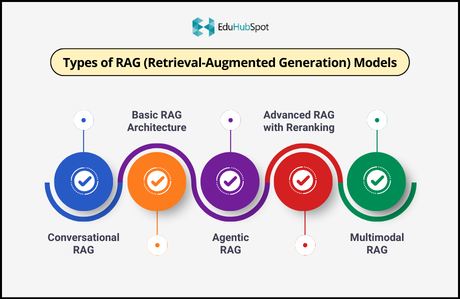
Different use cases require different RAG architectures. Here are the most common types.
Basic RAG Architecture
This is the classic retrieval → generation pipeline.
Simple and effective for most workloads.
Advanced RAG with Reranking
Large enterprises often use rerankers to refine retrieval results.
This improves accuracy by ensuring the LLM sees only the best information.
Conversational RAG
For chatbots and assistants that maintain multi-turn conversation history.
The system retrieves new information based on evolving context.
Agentic RAG
Here, the AI acts like an agent who retrieves, analyzes, decides, and refines answers. This becomes important for research assistants, analysts, and autonomous tools.
Multimodal RAG
Not limited to text—this version retrieves:
- Images
- charts
- audio
- video transcripts
- tables
- graphs
This unlocks advanced applications like medical imaging analysis or financial data interpretation.
Real-World Applications of RAG (Retrieval-Augmented Generation)
Customer Service Automation
RAG-powered bots can search product manuals, help centers, and policy documents to deliver accurate answers without the risk of outdated or inconsistent information.
Healthcare and Medical Support
Doctors can use RAG systems to access:
- clinical guidelines
- medical literature
- treatment protocols
This reduces the risk and improves patient care.
Compliance, Legal, and Finance
With the regulatory platform changing continuously, RAG (Retrieval-Augmented Generation) systems provide analysts with access to reliable, up-to-date information and also provide access to official documentation.
Software Engineering and DevOps
Developers benefit from assistants who can:
- search documentation
- understand codebases
- reference API specs
- suggest solutions grounded in real examples
E-commerce and Product Discovery
RAG enhances product search, comparison, and personalized recommendation systems.
It can pull specifications, user reviews, and even warranty details.
Enterprise Knowledge Management
Companies with vast internal knowledge bases, like banks, telecom giants, and IT service providers, use RAG to make their information instantly accessible.
Research and Academic Work
A RAG-based assistant can retrieve academic papers, summarize literature, cross-reference data, and even provide citations.
Building a RAG (Retrieval-Augmented Generation) System
Here's what goes into developing a production-grade RAG pipeline.
Data Collection
Gather documents from:
- PDFs
- websites
- databases
- internal knowledge sources
- emails or support logs
Chunking
Large documents are broken into small, meaningful pieces.
Good chunking improves retrieval accuracy dramatically.
Embedding Generation
Each chunk is converted into an embedding vector.
Higher-quality embedding models lead to better search results.
Storing Embeddings in a Vector Database
A high-performance vector store indexes the embeddings.
Retrieval Mechanism
When users ask questions, the system retrieves the most relevant chunks.
Prompt and Context Engineering
Retrieved documents are merged into the LLM prompt in an optimized format.
Response Generation
The LLM generates a final answer that is factual, coherent, and grounded.
Let Us Talk Challenges and Limitations
RAG also brings its own challenges.
Retrieval Quality
Poor retrieval leads to poor answers. Even the best LLM can't compensate for bad data.
Pipeline Complexity
RAG requires managing embeddings, vector storage, retrieval logic, and LLM prompts. All of these require greater sophistication than working with LLMs by themselves.
Privacy and Compliance
Organizations must ensure sensitive data is:
- encrypted
- Access-controlled
- properly audited
Latency
Search + reranking + generation can make answers slower, though hardware improvements are solving this.
The Future of RAG (Retrieval-Augmented Generation)
You can see that the RAG paradigm is budding fast. Here's what the future may hold.
Self-Improving Retrieval
Future systems will learn which sources are most reliable and adjust retrieval behavior automatically.
Long-Term Memory Integration
AI agents will maintain memory, reducing repeated retrieval and improving personalization.
Agentic Workflows
RAG-powered AI will perform multi-step tasks:
- retrieve
- analyze
- plan
- validate
- act
Universal Multimodal Retrieval
RAG technology will integrate search functionality into all media: text, image, video, table, and structured data.
Fully Personalized AI
Your AI assistant will drive data based on your preferences, behavior, and history.
Final Thoughts
In many ways, RAG represents the future of intelligent systems. It bridges the world of generative AI with the world of real-time, factual data. RAG (Retrieval-Augmented Generation) delivers AI that is intelligent and trustworthy by overcoming the Knowledge Cut-off, reducing Hallucination, and giving models access to proprietary information.
In a scenario where organizations are running to derive the maximum value of their data, RAG will continue to survive as the most effective AI tools. It serves as an approach to accurate, dynamic, transparent, and deeply integrated in how we work.
If you are a developer building applications or a learner curious about AI, you must learn RAG (Retrieval-Augmented Generation) as it is not just a technique, but the base of the next AI revolution.
FAQs
What problem does RAG actually solve?
RAG is able to overcome the limitations of static LLMs because it uses real-time and reliable information, rather than relying on only outdated training data.
How does Retrieval-Augmented Generation reduce AI hallucinations?
It grounds responses in retrieved documents, ensuring the model references factual data instead of guessing.
Is RAG expensive to implement compared to retraining AI models?
No. Updating a vector database is far faster and cheaper than retraining an entire LLM.
Explore Our Latest
Insights

Stay updated with our recent blog posts.